Matrix rank is an important concept in linear algebra. While rank deficiency can be a sign of an incompletely or improperly specified problem (a singular system of linear equations, for example), in some problems low rank of a matrix is a desired property or outcome. Here we present some fundamental rank relations in a concise form useful for reference. These are all immediate consequences of the singular value decomposition (SVD), but we give elementary (albeit not entirely self-contained) proofs of them.
The rank of a matrix 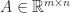


A rank-





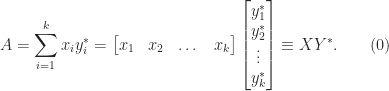
Each column of 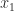
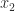

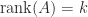

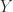

Here are some fundamental rank equalities and inequalities.
Rank-Nullity Theorem
The rank-nullity theorem says that

where 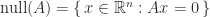
Rank Bound
The rank cannot exceed the number of columns, or, by (5) below, the number of rows:

Rank of a Sum
For any 

The upper bound follows from the fact that the dimension of the sum of two subspaces cannot exceed the sum of the dimensions of the subspaces. Interestingly, the upper bound is also a corollary of the bound (3) for the rank of a matrix product, because
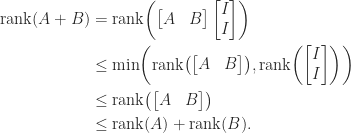
For the lower bound, writing 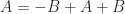
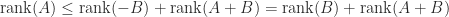
Rank of and 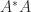
For any

Indeed 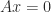


Rank of a General Product
For any 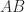

If ![B = [b_1,\dots,b_n]](https://s0.wp.com/latex.php?latex=B+%3D+%5Bb_1%2C%5Cdots%2Cb_n%5D&bg=ffffff&fg=222222&s=0&c=20201002)
![AB = [Ab_1,\dots,Ab_n]](https://s0.wp.com/latex.php?latex=AB+%3D+%5BAb_1%2C%5Cdots%2CAb_n%5D&bg=ffffff&fg=222222&s=0&c=20201002)
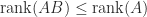
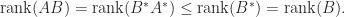
The latter inequality can be proved without using (5) (our proof of which uses (3)), as follows. Suppose 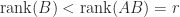




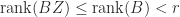
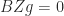
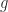


Rank of a Product of Full-Rank Matrices
We have

We note that 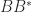

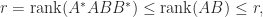
and hence 
Another important relation is

This is a consequence of the equality 
Ranks of and 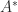
By (2) and (3) we have 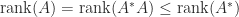


In other words, the rank of
Full-Rank Factorization
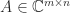
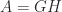




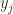


![Y = [y_1,y_2,\dots, y_n]](https://s0.wp.com/latex.php?latex=Y+%3D+%5By_1%2Cy_2%2C%5Cdots%2C+y_n%5D&bg=ffffff&fg=222222&s=0&c=20201002)

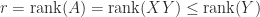


Rank and Minors
A characterization of rank that is sometimes used as the definition is that it is the size of the largest nonsingular square submatrix. Equivalently, the rank is the size of the largest nonzero minor, where a minor of size 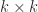
rank(AB) and rank(BA)
Although 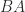


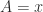
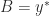



Note that 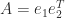

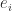


How to Find Rank
If we have a full-rank factorization of

where 
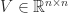
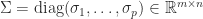

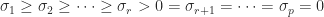
In floating-point arithmetic, the standard algorithms for computing the SVD are numerically stable, that is, the computed singular values are the exact singular values of a matrix 



>> n = 4; A = zeros(n); A(:) = 1:n^2, svd(A)
A =
1 5 9 13
2 6 10 14
3 7 11 15
4 8 12 16
ans =
3.8623e+01
2.0713e+00
1.5326e-15
1.3459e-16
The matrix has rank 

rank function computes the rank as the number of singular values exceeding 

References
An excellent reference for further rank relations is Horn and Johnson. Stewart describes some of the issues associated with rank-deficient matrices in practical computation.
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. My review of the second edition.
- G. W. Stewart, Rank Degeneracy, SIAM J. Sci. Statist. Comput. 5 (2), 403–413, 1984
