
The singular value decomposition (SVD) is one of the most important tools in matrix theory and matrix computations. It is described in many textbooks and is provided in all the standard numerical computing packages. I wrote a two-page article about the SVD for The Princeton Companion to Applied Mathematics, which can be downloaded in pre-publication form as an EPrint.
The polar decomposition is a close cousin of the SVD. While it is probably less well known it also deserves recognition as a fundamental theoretical and computational tool. The polar decomposition is the natural generalization to matrices of the polar form 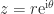

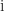
![\theta\in(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002)



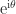

It is easy to prove existence and uniqueness of the polar decomposition when 
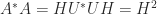
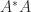

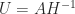
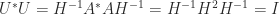
Many applications of the polar decomposition stem from a best approximation property: for any
However, a more trivial property of the polar decomposition is also proving to be important. Suppose we are given 



Yuji Nakatsukasa and I recently revisited this idea. In a 2013 paper in the SIAM Journal of Scientific Computing we showed that on modern architectures it is possible to compute the SVD via the polar decomposition in a way that is both numerically stable and potentially much faster than the standard Golub–Reinsch SVD algorithm. Our algorithm has two main steps.
- Compute the polar decomposition by an accelerated Halley algorithm called QDWH devised by Nakatsukasa, Bai, and Gygi (2010), for which the main computational kernel is QR factorization.
- Compute the eigendecomposition of the Hermitian polar factor by a spectral divide and conquer algorithm. This algorithm repeatedly applies QDWH to the current block to compute an invariant subspace corresponding to the positive or negative eigenvalues and thereby divides the problem into two smaller pieces.
The polar decomposition is fundamental to both steps of the algorithm. While the total number of flops required is greater than for the standard SVD algorithm, the new algorithm has lower communication costs and so should be faster on parallel computing architectures once communication costs are sufficiently greater than the costs of floating point arithmetic. Sukkari, Ltaief, and Keyes have recently shown that on a multicore architecture enhanced with multiple GPUs the new QDWH-based algorithm is indeed faster than the standard approach. Another interesting feature of the new algorithm is that it has been found experimentally to have better accuracy.
The Halley iteration that underlies the QDWH algorithm for the polar decomposition has cubic convergence. A version of QDWH with order of convergence seventeen, which requires just two iterations to converge to double-precision accuracy, has been developed by Nakatsukasa and Freund (2015), and is aimed particularly at parallel architectures. This is a rare example of an iteration with a very high order of convergence actually being of practical use.
