The Numerical Analysis Group at the University of Manchester held a two-day Creativity Workshop at Shrigley Hall in the Cheshire countryside at the end of May 2013. All of the numerical analysis staff, postdocs and PhD students attended, along with two external collaborators from NAG and the Rutherford Appleton Laboratory.
After successfully piloting creativity workshops in 2010 under the Creativity@Home banner, the Engineering and Physical Sciences Research Council (EPSRC) now encourages holders of large grants to exploit creativity training.
A creativity workshop is an event in which a group of people tackle questions using a structured approach that encourages innovative ideas to be generated and carefully assessed and developed. It avoids the trap that we readily fall into of evaluating ideas too soon. Such an event needs an experienced facilitator who understands the nature of creativity and can skillfully guide the participants through the steps of tackling problems.
We were fortunate to have as our guide Dennis Sherwood, a leading expert on creativity who has worked with a wide variety of organizations including Manchester United, the National Grid and the European Commission, and who is recommended by EPSRC (indeed Dennis previously led an EPSRC-funded creativity workshop in 2010 that I attended as part of the Manchester CICADA team).

Dennis provides participants with a day of creativity training before a workshop. He quotes Koestler’s law (from The Act of Creation, 1964):
The creative act is not an act of creation in the sense of the Old Testament.
It does not create something out of nothing.
It uncovers, selects, reshuffles, combines, synthesizes, already
existing facts, ideas, faculties, skills.
The more familiar the parts the more striking the new whole.
He points out a problem with Koestler’s definition: it assumes that the sub-assemblies that are selected, reshuffled, and so on, are already explicitly there. In practice they are usually there within existing patterns, and may not be so obvious. He formulates Sherwood’s Law:
Creativity is the process of forming new patterns from pre-existing
component parts. The more the resulting pattern shows emergent
properties, such as those of beauty, utility, or value,
the more powerful the corresponding idea.
So creativity does not necessarily need new ideas (in any case, we usually don’t know if an idea is novel), but is about taking existing ideas and combining them in new and unanticipated ways. Dennis’s training days and his books 1, 2 explain the principles of creativity and the workshops themselves help put them into practice.
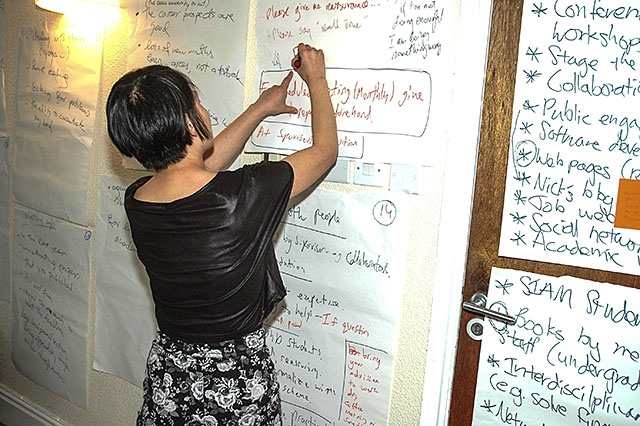
At our workshop a number of questions were addressed, including “Being a magnet for talent”, “The undergraduate curriculum”, “Software and programming languages”, “The PhD experience”, as well as strategic plans for the group and plans for future research projects and grant proposals.
By the end of an exhausting workshop many ideas had been generated and assessed and the group is now planning the next steps with the help of the detailed 94-page written report produced by Dennis.
Despite some understandable initial skepticism among some attendees new to the creativity workshop concept, everyone participated fully and enjoyed the experience. I thoroughly recommend such a workshop to other research groups.


Photo credits: Nick Higham (1,4), Dennis Sherwood (2,3).
















 and compile to PDF. Key here is Org’s ability to easily add or remove rows and columns, sort rows, and even transpose a table (see below). This blog is written in Org mode and exported to WordPress using
and compile to PDF. Key here is Org’s ability to easily add or remove rows and columns, sort rows, and even transpose a table (see below). This blog is written in Org mode and exported to WordPress using 
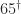
 The master bibliography of the fourth edition is not printed in the book but is downloadable from the book’s
The master bibliography of the fourth edition is not printed in the book but is downloadable from the book’s 

 . The scalar Lambert W function was named and popularized in a 1996 paper by Corless, Gonnet, Hare, Jeffrey and Knuth,
. The scalar Lambert W function was named and popularized in a 1996 paper by Corless, Gonnet, Hare, Jeffrey and Knuth,  Mary Aprahamian presented a new matrix function called the
Mary Aprahamian presented a new matrix function called the 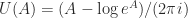 , which arises from the scalar unwinding number introduced by Corless, Hare and Jeffrey in 1996. She showed that it is useful as a means for obtaining correct identities involving multivalued functions at matrix arguments, as well as being useful for argument reduction in evaluating the matrix exponential.
, which arises from the scalar unwinding number introduced by Corless, Hare and Jeffrey in 1996. She showed that it is useful as a means for obtaining correct identities involving multivalued functions at matrix arguments, as well as being useful for argument reduction in evaluating the matrix exponential. 

 with
with  elements the sample variance is
elements the sample variance is  , where the sample mean is
, where the sample mean is 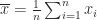 . An alternative formula often given in textbooks is
. An alternative formula often given in textbooks is 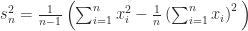 . This second formula has the advantage that it can be computed with just one pass through the data, whereas the first formula requires two passes. However, the one-pass formula can suffer damaging subtractive cancellation, making it numerically unstable. When I wrote my book
. This second formula has the advantage that it can be computed with just one pass through the data, whereas the first formula requires two passes. However, the one-pass formula can suffer damaging subtractive cancellation, making it numerically unstable. When I wrote my book ![x = [m, m+1, m+2]](https://s0.wp.com/latex.php?latex=x+%3D+%5Bm%2C+m%2B1%2C+m%2B2%5D&bg=ffffff&fg=222222&s=0&c=20201002) (Google Sheets does not seem to have a built-in function for the sample variance; the standard deviation is the square root of the sample variance). Here is what I found. (The spreadsheet that produced these results is available
(Google Sheets does not seem to have a built-in function for the sample variance; the standard deviation is the square root of the sample variance). Here is what I found. (The spreadsheet that produced these results is available 


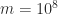 is what I would expect from the one-pass formula in IEEE double precision arithmetic, which has the equivalent of about 16 significant decimal digits of precision, since
is what I would expect from the one-pass formula in IEEE double precision arithmetic, which has the equivalent of about 16 significant decimal digits of precision, since  and
and  are both about
are both about 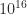 and so there is not enough precision to retain the difference (which is equal to 2). A computation in MATLAB verifies that the one-pass formula returns 0 in IEEE double precision arithmetic.
and so there is not enough precision to retain the difference (which is equal to 2). A computation in MATLAB verifies that the one-pass formula returns 0 in IEEE double precision arithmetic. 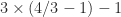 evaluates to 2.2E-16. So it appears that Google may be using the one-pass formula.
evaluates to 2.2E-16. So it appears that Google may be using the one-pass formula.  The conference venue. Note the residual snow, which fortunately did not fall in any serious amounts during the conference.
The conference venue. Note the residual snow, which fortunately did not fall in any serious amounts during the conference.  The poster session of about 65 posters was preceded by a poster blitz (1 minute presentations) and was accompanied by an excellent dessert. This photo shows Edvin Deadman (University of Manchester and NAG Ltd.) discussing his poster on Matrix Functions and the NAG Library with Cleve Moler and Charlie Van Loan (authors of the classic
The poster session of about 65 posters was preceded by a poster blitz (1 minute presentations) and was accompanied by an excellent dessert. This photo shows Edvin Deadman (University of Manchester and NAG Ltd.) discussing his poster on Matrix Functions and the NAG Library with Cleve Moler and Charlie Van Loan (authors of the classic  Josh Bloom’s (UC Berkeley) invited presentation
Josh Bloom’s (UC Berkeley) invited presentation  It was interesting to see MapReduce being used to implement numerical algorithms, notably in the minisymposium
It was interesting to see MapReduce being used to implement numerical algorithms, notably in the minisymposium  Here is the lunchtime panel
Here is the lunchtime panel 
{kind=link}