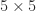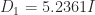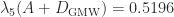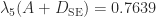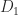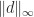Suppose  is a matrix that is symmetric but not positive definite. What is the best way to perturb the diagonal to make positive definite? We want to compute a vector
is a matrix that is symmetric but not positive definite. What is the best way to perturb the diagonal to make positive definite? We want to compute a vector 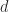 such that
such that

is positive definite. Since the positive definite matrices form an open set there is no minimal , so we relax the requirement to be that is positive semidefinite. The perturbation  needs to make any negative eigenvalues of become nonnegative. We will require all the entries of to be nonnegative. Denote the eigenvalues of by
needs to make any negative eigenvalues of become nonnegative. We will require all the entries of to be nonnegative. Denote the eigenvalues of by 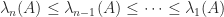 and assume that
and assume that  .
.
A natural choice is to take to be a multiple of the identity matrix. For  ,
,  has eigenvalues
has eigenvalues  , and so the smallest possible
, and so the smallest possible 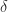 is
is 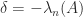 . This choice of shifts all the diagonal elements by the same amount, which might be undesirable for a matrix with widely varying diagonal elements.
. This choice of shifts all the diagonal elements by the same amount, which might be undesirable for a matrix with widely varying diagonal elements.
When the diagonal entries of are positive another possibility is to take  , so that each diagonal entry undergoes a relative perturbation of size
, so that each diagonal entry undergoes a relative perturbation of size  . Write
. Write  and note that
and note that  is symmetric with unit diagonal. Then
is symmetric with unit diagonal. Then
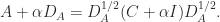
Since  is positive semidefinite if and only if
is positive semidefinite if and only if  is positive semidefinite, the smallest possible is
is positive semidefinite, the smallest possible is 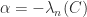 .
.
More generally, we can treat the  as
as  independent variables and ask for the solution of the optimization problem
independent variables and ask for the solution of the optimization problem
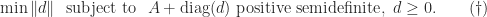
Of particular interest are the norms  (since
(since 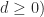 and
and  .
.
If 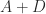 is positive semidefinite then from standard eigenvalue inequalities,
is positive semidefinite then from standard eigenvalue inequalities,

so that

Since 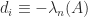 satisfies the constraints of
satisfies the constraints of 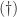 , this means that this solves for the
, this means that this solves for the  -norm, though the solution is obviously not unique in general.
-norm, though the solution is obviously not unique in general.
For the  – and
– and  -norms, does not have an explicit solution, but it can be solved by semidefinite programming techniques.
-norms, does not have an explicit solution, but it can be solved by semidefinite programming techniques.
Another approach to finding a suitable is to compute a modified Cholesky factorization. Given a symmetric , such a method computes a perturbation 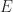 such that
such that  for an upper triangular
for an upper triangular  with positive diagonal elements, so that
with positive diagonal elements, so that  is positive definite. The methods of Gill, Murray, and Wright (1981) and Schnabel and Eskow (1990) compute a diagonal . The cost in flops is essentially the same as that of computing a Cholesky factorization (
is positive definite. The methods of Gill, Murray, and Wright (1981) and Schnabel and Eskow (1990) compute a diagonal . The cost in flops is essentially the same as that of computing a Cholesky factorization (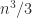 ) flops), so this approach is likely to require fewer flops than computing the minimum eigenvalue or solving an optimization problem, but the perturbations produces will not be optimal.
) flops), so this approach is likely to require fewer flops than computing the minimum eigenvalue or solving an optimization problem, but the perturbations produces will not be optimal.
References
- Roger Fletcher, Semi-Definite Matrix Constraints in Optimization, SIAM J. Control Optim. 23 (4), 493–513, 1985.
- Philip Gill, Walter Murray, and Margaret Wright, Practical Optimization, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2020. Republication of book first published by Academic Press, 1981.
- Robert Schnabel and Elizabeth Eskow, A Revised Modified Cholesky Factorization Algorithm, SIAM J. Optim. 9(4), 1135–1148, 1999.