Newton methods for minimizing a function 



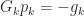


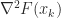

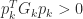
A modified Cholesky factorization of a symmetric matrix 
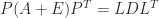




A natural way to compute a modified Cholesky factorization is to modify the Cholesky factorization algorithm. Cholesky factorization fails when it tries to take the square root of a negative quantity or divide by zero. We can avoid both possibilities by increasing nonpositive pivots when they are encountered. This corresponds to making a diagonal perturbation 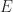
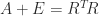
Consider the matrix
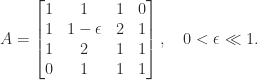
Since Cholesky factorization generates the same sequence of Schur complements as Gaussian elimination, it suffices to consider Gaussian elimination. The diagonal elements of 
![\notag A^{(2)} = \left[\begin{array}{c|ccc} 1 & 1 & 1 & 1\\\hline 0 & -\epsilon & 1 & 1\\ 0 & 1 & 0 & 1\\ 0 & 1 & 1 & 1 \end{array}\right],](https://s0.wp.com/latex.php?latex=%5Cnotag+++A%5E%7B%282%29%7D+%3D+++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7Cccc%7D++++1+%26+1++++++++++%26+1+%26+1%5C%5C%5Chline++++0+%26+-%5Cepsilon+%26++1+++%26+1%5C%5C++++0+%26++1++++++++++%26+0+%26+1%5C%5C++++0+%26+++1+++++++++%26+1+%26+1+++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
and the trailing 

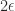
![\notag A^{(2)} + E = \left[\begin{array}{c|ccc} 1 & 1 & 1 & 1\\\hline 0 & \epsilon & 1 & 1\\ 0 & 1 & 0 & 1\\ 0 & 1 & 1 & 1 \end{array}\right] \quad (E = 2 \mskip1mu\epsilon \mskip1mu e_2e_2^T).](https://s0.wp.com/latex.php?latex=%5Cnotag+++A%5E%7B%282%29%7D+%2B+E+%3D+++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7Cccc%7D++++1+%26+1++++++++++%26+1+%26+1%5C%5C%5Chline++++0+%26+%5Cepsilon+%26+1+++%26+1%5C%5C++++0+%26+1+++++++++++%26+0+%26+1%5C%5C++++0+%26+1+++++++++++%26+1+%26+1+++%5Cend%7Barray%7D%5Cright%5D+++%5Cquad+++%28E+%3D++2+%5Cmskip1mu%5Cepsilon+%5Cmskip1mu+e_2e_2%5ET%29.+&bg=ffffff&fg=222222&s=0&c=20201002)
The next stage of the factorization can complete and it yields
![\notag A^{(3)} = \left[\begin{array}{cc|cc} 1 & 1 & 1 & 1 \\ 0 & \epsilon & 1 & 1 \\\hline\rule{0cm}{18pt} 0 & 0 & -\displaystyle\frac{1}{\epsilon} & 1 - \displaystyle\frac{1}{\epsilon}\\\rule{0cm}{20pt} 0 & 0 &1 - \displaystyle\frac{1}{\epsilon} & 1 - \displaystyle\frac{1}{\epsilon} \end{array}\right],](https://s0.wp.com/latex.php?latex=%5Cnotag+++A%5E%7B%283%29%7D+%3D+++%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7Ccc%7D++++1+%26+1++++++++++%26+1+%26+1+%5C%5C++++0+%26+%5Cepsilon+++%26+1+%26+1+%5C%5C%5Chline%5Crule%7B0cm%7D%7B18pt%7D++++0+%26+0++++++++++%26+-%5Cdisplaystyle%5Cfrac%7B1%7D%7B%5Cepsilon%7D+%26+1+-+%5Cdisplaystyle%5Cfrac%7B1%7D%7B%5Cepsilon%7D%5C%5C%5Crule%7B0cm%7D%7B20pt%7D++++0+%26+0++++++++++%261+-+%5Cdisplaystyle%5Cfrac%7B1%7D%7B%5Cepsilon%7D+%26++1+-+%5Cdisplaystyle%5Cfrac%7B1%7D%7B%5Cepsilon%7D+++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
The trailing 
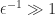
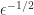


This example shows that if we are to increase a pivot element then we need a more sophisticated strategy that takes account of the size of the resulting elements of the factors and the effect on later stages of the factorization.
A modified Cholesky factorization should satisfy, as far as possible, four objectives.
- If
- If
is not much larger than
for some appropriate norm.
- The matrix
- The cost of the algorithm is the same as the cost of standard Cholesky factorization, that is,
flops for an
matrix.
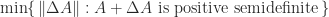
Gill and Murray (1974) gave the first modified Cholesky algorithm, which computes
A different approach was taken by Cheng and Higham (1998), building on an earlier idea by Bunch and Sorensen. This approach computes a block 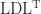




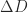
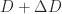
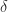
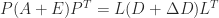
A significant advantage of the block
Modified Cholesky software is not widely available in libraries. Implementations of the Cheng–Higham algorithm are available in
- the NAG Library routine f01mdf (
real_modified_cholesky), - the MATLAB codes in the repository https://github.com/higham/modified-cholesky.
Example
We take the 
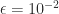
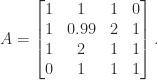
It has eigenvalues
-1.0050e+00 -2.3744e-01 1.0000e+00 4.2325e+00
The Gill–Murray–Wright algorithm computes as
0 2.0200e+00 2.0000e+00 0
while the Schnabel–Eskow algorithm (1999) computes
1.0000e+00 1.0050e+00 1.0050e+00 1.0000e+00
For the Cheng–Higham algorithm with 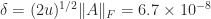

1.0000e+00 1.0000e+00 1.0000e+00 0
1.0000e+00 1.4950e+00 1.4975e+00 9.9749e-01
1.0000e+00 1.4975e+00 1.5000e+00 1.0025e+00
0 9.9749e-01 1.0025e+00 2.0100e+00
The Frobenius norms of the perturbations to 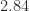

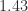
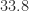
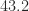

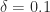
1.0000e+00 1.0000e+00 1.0000e+00 0
1.0000e+00 1.5453e+00 1.4475e+00 9.9724e-01
1.0000e+00 1.4475e+00 1.5497e+00 1.0027e+00
0 9.9724e-01 1.0027e+00 2.1100e+00
at Frobenius norm distance 
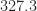

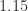
In general, there is no clear ordering of the different modified Cholesky methods in terms of their ability to satisfy the four criteria.
References
This is a minimal set of references, which contain further useful references within.
- Sheung Hun Cheng and Nicholas Higham, A Modified Cholesky Algorithm Based on a Symmetric Indefinite Factorization, SIAM J. Matrix Anal. Appl. 19(4), 1097–1110, 1998.
- Haw-Ren Fang and Dianne O’Leary, Modified Cholesky Algorithms: A Catalog with New Approaches, Math. Program. 115, 319–349, 2008
- Philip Gill, Walter Murray, and Margaret Wright, Practical Optimization, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2020. Republication of book first published by Academic Press, 1981.
- Thomas McSweeney, Modified Cholesky Decomposition and Applications, M.Sc. Thesis, The University of Manchester, 2017.
- Robert Schnabel and Elizabeth Eskow, A Revised Modified Cholesky Factorization Algorithm, SIAM J. Optim. 9(4), 1135–1148, 1999.
Related Blog Posts
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

When you give the cost of the Cholesky factorization, do you mean o(n^3) (little-o), rather than O(n^3) (big-O) ?
That was indeed a typo: n^3/3 + O(n^3) now changed to n^/3 + O(n^2).