The softmax function takes as input a real 

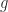

It arises in machine learning, game theory, and statistics. Since 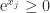
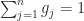
The softmax function is the gradient of the log-sum-exp function

where 
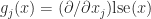
The following plots show the two components of softmax for 
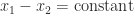

Here are some examples:
>> softmax([-1 0 1]) ans = 9.0031e-02 2.4473e-01 6.6524e-01 >> softmax([-1 0 10]) ans = 1.6701e-05 4.5397e-05 9.9994e-01
Note how softmax increases the relative weighting of the larger components over the smaller ones. The MATLAB function softmax used here is available at https://github.com/higham/logsumexp-softmax.
A concise alternative formula, which removes the denominator of 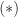
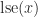

Straightforward evaluation of softmax from either 
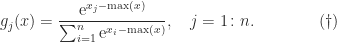
where 
References
This is a minimal set of references, which contain further useful references within.
- Pierre Blanchard, Desmond J. Higham, and Nicholas J. Higham, Accurately Computing the Log-Sum-Exp and Softmax Functions, IMA J. Numer. Anal., Advance access, 2020.
- Bolin Gao and Lacra Pavel, On the Properties of the Softmax Function with Application in Game Theory and Reinforcement Learning, ArXiv:1209.5145, 2018.
- Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Deep Learning, MIT Press, 2016.
Related Blog Posts
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
