
The matrix exponential is a ubiquitous matrix function, important both for theory and for practical computation. The matrix logarithm, an inverse to the exponential, is also increasingly used (see my earlier post, 400 Years of Logarithms).
MATLAB R2015b introduced new versions of the expm and logm functions. The Release Notes say
The algorithms for expm, logm, and sqrtm show increased accuracy, with logm and sqrtm additionally showing improved performance.
The help text for expm and logm is essentially unchanged from the previous versions, so what’s different about the new functions? (I will discuss sqrtm in a future post.)
The answer is that both functions make use of new backward error bounds that can be much smaller than the old ones for very nonnormal matrices, and so help to avoid a phenomenon known as overscaling. The key change is that when bounding a matrix power series 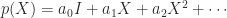


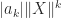
This is best illustrated by example. Suppose we want to bound 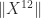



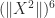



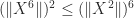
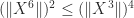

This argument can be generalized so that every power of 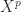


We have 
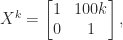
so the bound above is roughly 
One way to understand what is happening is to note the inequality

where 
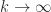
What is the effect of these bounds on the algorithms in expm and logm? Both algorithms make use of Padé approximants, which are good only for small-normed matrices, so the algorithms begin by reducing the norm of the input matrix. Backward error bounds derived by bounding a power series as above guide the norm reduction and if the bounds are weak then the norm is reduced too much, which can result in loss of accuracy in floating point arithmetic—the phenomenon of overscaling. The new bounds greatly reduce the chance of overscaling.
In his blog post A Balancing Act for the Matrix Exponential, Cleve Moler describes a badly scaled 3-by-3 matrix for which the original expm suffers from overscaling and a loss of accuracy, but notes that the new algorithm does an excellent job.
The new logm has another fundamental change: it applies inverse scaling and squaring and Padé approximation to the whole triangular Schur factor, whereas the previous logm applied this technique to the individual diagonal blocks in conjunction with the Parlett recurrence.
For more on the algorithms underlying the new codes see these papers. The details of how the norm of a matrix power series is bounded are given in Section 4 of the first paper.
- A. H. Al-Mohy and N. J. Higham. A new scaling and squaring algorithm for the matrix exponential, SIAM J. Matrix Anal. Appl. 31(3), 970–989, 2009.
- A. H. Al-Mohy and N. J. Higham. Improved inverse scaling and squaring algorithms for the matrix logarithm, SIAM J. Sci. Comp. 34(4), 153–169, 2012.
- A. H. Al-Mohy, N. J. Higham and S. D. Relton. Computing the Fréchet derivative of the matrix logarithm and estimating the condition number, SIAM J. Sci. Comp. 35(4), 394–410, 2013.
