The matrix inverse is defined only for square nonsingular matrices. A generalized inverse is an extension of the concept of inverse that applies to square singular matrices and rectangular matrices. There are many definitions of generalized inverses, all of which reduce to the usual inverse when the matrix is square and nonsingular.
A large class of generalized inverses of an 


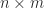
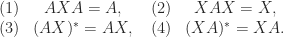
Here, the superscript 
Condition (1) implies that if 

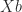
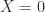
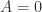
A (1,3) inverse can be shown to provide a least squares solution to an inconsistent linear system. A (1,4) inverse can be shown to provide the minimum 2-norm solution of a consistent linear system (where the 2-norm is defined by 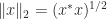
There is not a unique matrix satisfying any one, two, or three of the Moore–Penrose conditions. But there is a unique matrix satisfying all four of the conditions, and it is called the Moore-Penrose pseudoinverse, denoted by 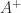
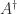
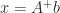
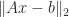
The pseudoinverse can be expressed in terms of the singular value decomposition (SVD). If 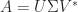
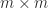






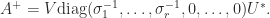
In MATLAB, the function pinv computes 

For square matrices, the Drazin inverse is the unique matrix 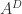
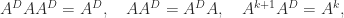
where 


If 
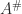
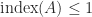
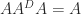
The Drazin inverse can be represented explicitly as follows. If
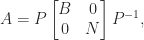
where 

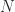
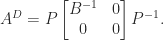
Here is the pseudoinverse and the Drazin inverse for a particular matrix with index 
![A = \left[\begin{array}{rrr} 1 & -1 & -1\\[3pt] 0 & 0 & -1\\[3pt] 0 & 0 & 0 \end{array}\right], \quad A^+ = \left[\begin{array}{rrr} \frac{1}{2} & -\frac{1}{2} & 0\\[3pt] -\frac{1}{2} & \frac{1}{2} & 0\\[3pt] 0 & -1 & 0 \end{array}\right], \quad A^D = \left[\begin{array}{rrr} 1 & -1 & 0\\[3pt] 0 & 0 & 0\\[3pt] 0 & 0 & 0 \end{array}\right].](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+1+%26+-1+%26+-1%5C%5C%5B3pt%5D+0+%26+0+%26+-1%5C%5C%5B3pt%5D+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+A%5E%2B+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+%5Cfrac%7B1%7D%7B2%7D+%26+-%5Cfrac%7B1%7D%7B2%7D+%26+0%5C%5C%5B3pt%5D+-%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D+%26+0%5C%5C%5B3pt%5D+0+%26+-1+%26+0+%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+A%5ED+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+1+%26+-1+%26+0%5C%5C%5B3pt%5D+0+%26+0+%26+0%5C%5C%5B3pt%5D+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
Applications
The Moore–Penrose pseudoinverse is intimately connected with orthogonality, whereas the Drazin inverse has spectral properties related to those of the original matrix. The pseudoinverse occurs in all kinds of least squares problems. Applications of the Drazin inverse include population modelling, Markov chains, and singular systems of linear differential equations. It is not usually necessary to compute generalized inverses, but they are valuable theoretical tools.
References
This is a minimal set of references, which contain further useful references within.
- Adi Ben-Israel, The Moore of the Moore–Penrose Inverse, Electron. J. Linear Algebra 9, 150–157, 2002.
- Adi Ben-Israel and Thomas N. E. Greville, Generalized Inverses: Theory and Applications, second edition, Springer-Verlag, New York, 2003
- Stephen Campbell and Carl Meyer, Generalized Inverses of Linear Transformations, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2009. published (Originally published by Pitman in 1979.)
- Stephen J. Kirkland and Michael Neumann, Group Inverses and
-Matrices and their Applications, Chapman and Hall/CRC, 2013
- Guorong Wang, Yimin Wei and Sanzheng Qiao, Generalized Inverses: Theory and Computations, second edition, Springer-Verlag, Singapore, 2018.
Related Blog Posts
- What is a Matrix? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

Beautiful “What is” about the pseudoinverse. Well written, concise, accurate. It is an art to write an article about anything — a news story, for example — that is both concise and accurate.
I have one quibble. As you probably know, I am interested in mathematical typography. I see that you are not using MathJax or MathML, Why not? You don’t have mathematics, you have pictures of mathematics. All of the math, even the A’s and X’s, are little .png files. The inline math doesn’t have the proper baseline. The displayed math looks OK in my browser, but it is pixelated when you print it or enlarge it. I know you are interested in this topic as well. How have you decided to use whatever mathematical typesetting you are using?
Should I submit this, minus this question, as a comment.
I hope you and your family are well,
— Cleve
Thanks, Cleve. I’m using WordPress.com and it doesn’t support MathJax, apparently because it regards the required Javascript as a security risk. If I were to host my own WordPress installation (“WordPress.org”) I could install a MathJax plugin. I prefer to stick with WordPress.com for its ease of use. The relatively poor typesetting of math is why I’m making every “What Is” post available as a PDF file (see the end of each post). I actually write the posts in Emacs Org mode and export them to both WordPress (using Org2blog) and LaTeX.
FWIW on easy docs with Math (not suggesting you change your blog) this might be of interest to some people: https://casual-effects.com/markdeep/
Nice idea for a blog series. Thanks for doing it.