Sixty years ago James Wilkinson published his backward error analysis of Gaussian elimination for solving a linear system 


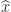
where 

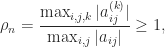
where the 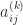


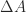
With partial pivoting, in which row interchanges are used to ensure that at each stage the pivot element is the largest in its column, Wilkinson showed that 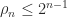
It is easy to experiment with growth factors in MATLAB. I will use the function
function g = gf(A) %GF Approximate growth factor. % g = GF(A) is an approximation to the % growth factor for LU factorization % with partial pivoting. [~,U] = lu(A); g = max(abs(U),[],'all')/max(abs(A),[],'all');
It computes a lower bound on the growth factor (since it only considers 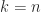
>> rng(1); n = 10000; gf(randn(n)) ans = 6.1335e+01
Growth of 61 is unremarkable for a matrix of this size. Now we try a matrix of the same size generated by the gallery('randsvd') function:
>> A = gallery('randsvd',n,1e6,2,[],[],1);
>> gf(A)
ans =
9.7544e+02
This function generates an 1e6 specifies the 2-norm condition number, while the 2 (the mode parameter) specifies that there is only one small singular value, so the singular values are 1 repeated 
It turns out that mode 2 randsvd matrices generate with high probability growth factors of size at least 
>> gf(A(:,randperm(n))) ans = 7.8395e+02
Here is a plot showing the maximum over 12 randsvd matrices for each 
rand and randn matrices. The black curve is

What is the explanation for this large growth? It stems from three facts.
- Haar distributed orthogonal matrices have the property that that their elements are fairly small with high probability, as shown by Jiang in 2005.
- If the largest entries in magnitude of
are both small, in the sense that their product is
, then
for any pivoting strategy. This was proved by Des Higham and I in the paper Large Growth Factors in Gaussian Elimination with Pivoting.
- If
is an orthogonal matrix generating large growth then a rank-1 perturbation of 2-norm at most 1 tends to preserve the large growth.
For full details see the new EPrint Random Matrices Generating Large Growth in LU Factorization with Pivoting by Des Higham, Srikara Pranesh and me.
Is growth of order
- The largest dense linear systems
. If we work in single precision then
and so LU factorization can potentially be completely unstable if there is growth of order
- For IEEE half precision arithmetic growth of order
. It was overflow in half precision LU factorization on randsvd matrices that alerted us to the large growth.
 , as can be seen by taking norms, so let us concentrate on the smallest singular value.
, as can be seen by taking norms, so let us concentrate on the smallest singular value.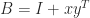 , for unit norm
, for unit norm  and
and  . The matrix
. The matrix  has eigenvalues 1 (repeated
has eigenvalues 1 (repeated 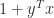 . The matrix is singular—and hence has a zero singular value—precisely when
. The matrix is singular—and hence has a zero singular value—precisely when 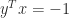 , which is the smallest value that the inner product
, which is the smallest value that the inner product 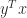 can take.
can take.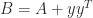 , where
, where 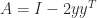 and
and 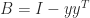 is singular with null vector
is singular with null vector 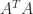 , which is the identity plus a rank-
, which is the identity plus a rank-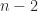 singular values remain at 1.
singular values remain at 1. and
and 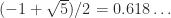 respectively! As our example shows,
respectively! As our example shows,  to be unit-norm random vectors with independent entries from the same distribution.
to be unit-norm random vectors with independent entries from the same distribution. with elements
with elements
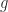 are all between
are all between  and
and  and they sum to 1, so
and they sum to 1, so 
 of the vector
of the vector  and
and  .
. because of the exponentials, even though
because of the exponentials, even though 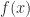 is very unlikely to do so.
is very unlikely to do so. , and use the formulas
, and use the formulas

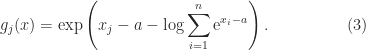
 ? Second, in (1) and (3),
? Second, in (1) and (3),  is negative can there be damaging subtractive cancellation?
is negative can there be damaging subtractive cancellation?

 . This has led to the development of an alternative 16-bit format that trades precision for range. The
. This has led to the development of an alternative 16-bit format that trades precision for range. The  . The series diverges, but when summed in the natural order in floating-point arithmetic it converges, because the partial sums grow while the addends decrease and eventually the addend is small enough that it does not change the partial sum. Here is a table showing the computed sum of the harmonic series for different precisions, along with how many terms are added before the sum becomes constant.
. The series diverges, but when summed in the natural order in floating-point arithmetic it converges, because the partial sums grow while the addends decrease and eventually the addend is small enough that it does not change the partial sum. Here is a table showing the computed sum of the harmonic series for different precisions, along with how many terms are added before the sum becomes constant.




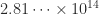

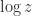 , for a complex number
, for a complex number  . It uses the arctan function to obtain the argument of a complex number.
. It uses the arctan function to obtain the argument of a complex number.
![(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002) for the principal value), and the code uses
for the principal value), and the code uses  ). The latter error suggests to me that the code had never actually been run, as for almost any argument it would produce an incorrect value. This is perhaps not surprising since Algol 60 compilers must have only just started to become available in 1961.
). The latter error suggests to me that the code had never actually been run, as for almost any argument it would produce an incorrect value. This is perhaps not surprising since Algol 60 compilers must have only just started to become available in 1961.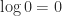 and has a missing minus sign in one statement. Finally, Collens gives in
and has a missing minus sign in one statement. Finally, Collens gives in
 s:
s: factor in the LU factorization with partial pivoting of
factor in the LU factorization with partial pivoting of 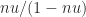 , with
, with  , where
, where 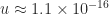 is the unit roundoff, and this is comfortably larger than the actual relative error (which also includes the errors in computing
is the unit roundoff, and this is comfortably larger than the actual relative error (which also includes the errors in computing  . Therefore the computed determinant is well within the bounds of roundoff, and if the exact result had not been an integer the incorrect last decimal digit would hardly merit discussion.
. Therefore the computed determinant is well within the bounds of roundoff, and if the exact result had not been an integer the incorrect last decimal digit would hardly merit discussion.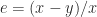 . I recently came across a program in which
. I recently came across a program in which  . It had never occurred to me to compute it this way. The second version is slightly easier to type, requiring no parentheses, and it has the same cost of evaluation: one division and one subtraction. Is there any reason not to use this parenthesis-free expression?
. It had never occurred to me to compute it this way. The second version is slightly easier to type, requiring no parentheses, and it has the same cost of evaluation: one division and one subtraction. Is there any reason not to use this parenthesis-free expression? 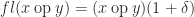 with
with  , where
, where 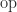 is any one of the four elementary arithmetic operations and
is any one of the four elementary arithmetic operations and  we obtain, with a hat denoting a computed quantity,
we obtain, with a hat denoting a computed quantity, 

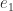 is computed very accurately.
is computed very accurately. 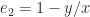 , we have
, we have 

 is of order
is of order  , and hence is very large when
, and hence is very large when  .
.  , we evaluated the relative error of
, we evaluated the relative error of 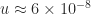 . (The MATLAB script that generates the figure is available as
. (The MATLAB script that generates the figure is available as 
 is very inaccurate when
is very inaccurate when  retains its accuracy as
retains its accuracy as  even the order of magnitude is incorrect for
even the order of magnitude is incorrect for  should be preferred.
should be preferred. 
 , and the iterates
, and the iterates  ) except where stated.
) except where stated. flops at single precision and
flops at single precision and  flops at double precision. Algorithm New, however, does
flops at double precision. Algorithm New, however, does 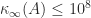 and it yields a forward error (defined by
and it yields a forward error (defined by  , where
, where 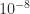 (as shown by standard analysis). Our new rounding error analysis shows that Algorithm New has the same error bounds, but has the more stringent requirement
(as shown by standard analysis). Our new rounding error analysis shows that Algorithm New has the same error bounds, but has the more stringent requirement  for convergence.
for convergence.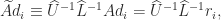
 are done at double precision and all other computations are done at single precision. Algorithm New now converges as long as
are done at double precision and all other computations are done at single precision. Algorithm New now converges as long as 

