by Erin Carson and Nick Higham

With the growing availability of half precision arithmetic in hardware and quadruple precision arithmetic in software, it is natural to ask whether we can harness these different precisions, along with the standard single and double precisions, to solve problems faster or more accurately.
We have been investigating this question for linear systems 

Iterative refinement is an old technique for improving the accuracy of an approximate solution to a linear system
We have found that using three different precisions, rather than the usual two, can bring major benefits. A scenario of particular interest is a mix of half precision, single precision, and double precision, with single precision the working precision in which 


Algorithm Trad: two-precision refinement (single, double).
Factorize $PA = LU$.
Solve $Ax_0 = b$ using the LU factors.
for $i=0:\infty$
Form $r_i = b - Ax_i$ in *double precision*
and round $r_i$ to *single precision*.
Solve $Ad_i = r_i$ using the LU factors.
$x_{i+1} = x_i + d_i$.
end
Algorithm New: three-precision refinement (half, single, double).
Factorize $PA = LU$ in *half precision*.
Solve $Ax_0 = b$ using the LU factors at *half precision*.
for $i=0:\infty$
Form $r_i = b - Ax_i$ in *double precision*
and round $r_i$ to *half precision*.
Solve $Ad_i = r_i$ at *half precision*
using the LU factors; store $d_i$ in *single*.
$x_{i+1} = x_i + d_i$.
end
Speed
Algorithm Trad does 

Accuracy
Algorithm Trad converges as long as 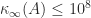


GMRES-IR
Now we replace the solve step in the loop of Algorithm New by an application of GMRES to the preconditioned system
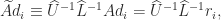
where matrix–vector products with 
Other Choices of Precision
Let H, S, D, and Q denote half precision, single precision, double precision, and quadruple precision, respectively. Algorithm New can be described as “HSD”, where the three letters indicate the precision of the factorization, the working precision, and the precision with which residuals are computed, respectively. Various combinations of letters produce feasible algorithms (20 in all, if we include fixed precision refinement algorithms, such as “SSS”), of which HSD, HSQ, HDQ and SDQ use three different precisions. Similar results to those above apply to the latter three combinations.
Outlook
Our MATLAB experiments confirm the predictions of the error analysis regarding the behavior of Algorithm New and its GMRES-IR variant. They also show that the number of GMRES iterations in GMRES-IR can indeed be small.
Iterative refinement in three precisions therefore offers great promise for speeding up the solution of
Full details of this work can be found in
Erin Carson and Nicholas J. Higham, Accelerating the Solution of Linear Systems by Iterative Refinement in Three Precisions MIMS EPrint 2017.24, Manchester Institute for Mathematical Sciences, The University of Manchester, UK, July 2017.
