The condition number of a matrix is a well known measure of ill conditioning that has been in use for many years. For an  matrix
matrix  it is
it is 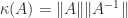 , where
, where  is any matrix norm. If is singular we usually regard the condition number as infinite.
is any matrix norm. If is singular we usually regard the condition number as infinite.
The first occurrences of the term “condition number” and of the formula that I am aware of are in Turing’s 1948 paper Rounding-Off Errors in Matrix Processes. He defines the  -condition number
-condition number 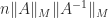 and the
and the 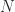 -condition number
-condition number  , where
, where  and
and 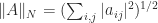 , the latter N-norm being what we now call the Frobenius norm. He suggests using these condition numbers to measure the ill conditioning of a matrix with respect to linear systems, using a statistical argument to make the connection. He also notes that “the best conditioned matrices are the orthogonal ones”.
, the latter N-norm being what we now call the Frobenius norm. He suggests using these condition numbers to measure the ill conditioning of a matrix with respect to linear systems, using a statistical argument to make the connection. He also notes that “the best conditioned matrices are the orthogonal ones”.
In his 1963 book Rounding Errors in Algebraic Processes, Wilkinson credits the first use of “condition number” to Turing and notes that “the term `ill-condition’ had been in common use among numerical analysts for some considerable time before this”. An early mention of linear equations being ill conditioned is in the 1933 paper An Electrical Calculating Machine by Mallock. According to Croarken, Mallock’s machine “could not adequately deal with ill conditioned equations, letting out a very sharp whistle when equilibrium could not be reached”.
As noted by Todd (The Condition of a Certain Matrix, 1950), von Neumann and Goldstine (in their monumental 1947 paper Numerical Inverting of Matrices of High Order) and Wittmeyer (1936) used the ratio of largest to smallest eigenvalue of a positive definite matrix in their analyses, which amounts to the 2-norm condition number 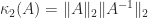 , though this formula is not used by these authors. Todd called this the
, though this formula is not used by these authors. Todd called this the  condition number. None of the , or names have stuck.
condition number. None of the , or names have stuck.
Nowadays we know that 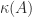 can be thought of both as a measure of the sensitivity of the solution of a linear system to perturbations in the data and as a measure of the sensitivity of the matrix inverse to perturbations in the matrix (see, for example, Condition Numbers and Their Condition Numbers by D. J. Higham). How to formulate the definition of condition number for a wide class of problems was worked out by John Rice in his 1966 paper A Theory of Condition.
can be thought of both as a measure of the sensitivity of the solution of a linear system to perturbations in the data and as a measure of the sensitivity of the matrix inverse to perturbations in the matrix (see, for example, Condition Numbers and Their Condition Numbers by D. J. Higham). How to formulate the definition of condition number for a wide class of problems was worked out by John Rice in his 1966 paper A Theory of Condition.

