One of the two or three largest books I have ever owned was recently delivered to me. The second edition of the Handbook of Linear Algebra, edited by Leslie Hogben (with the help of associate editors Richard Brualdi and G. W. (Pete) Stewart), comes in at over 1900 pages, 7cm thick and about half a kilogram. It is the same height and width, but much thicker than, the fourth edition of Golub and Van Loan’s Matrix Computations.
The second edition is substantially expanded from the 1400 page first edition of 2007, with 95 articles as opposed to the original 77. The table of contents and list of contributors is available at the book’s website.
The handbook aims to cover the major topics of linear algebra at both undergraduate and graduate level, as well as numerical linear algebra, combinatorial linear algebra, applications to different areas, and software.
The distinguished list of about 120 authors have produced articles in the CRC handbook style, which requires everything to be presented as a definition, a fact (without proof), an algorithm, or an example. As the author of the chapter on Functions of Matrices, I didn’t find this a natural style to write in, but one benefit is that it encourages the presentation of examples and the large number of illustrative examples is a characteristic feature of the book.
The 18 new chapters include
- Tensors and Hypermatrices by Lek-Heng Lim
- Matrix Polynomials by Joerg Liesen and Christian Mehl
- Matrix Equations by Beatrice Meini
- Invariant Subspaces by G. W. Stewart
- Tournaments by T. S. Michael
- Nonlinear Eigenvalue Problems by Heinrich Voss
- Linear Algebra in Mathematical Population Biology and Epidemiology by Fred Brauer and Carlos Castillo-Chavez
- Sage by Robert A. Bezer, Robert Bradshaw, Jason Grout, and William Stein
A notable absence from the applications chapters is network analysis, which in recent years has increasingly made use of linear algebra to define concepts such as centrality and communicability. However, it is impossible to cover every topic and in such a major project I would expect that some articles are invited but do not come to fruition by publication time.
The book is typeset in  , like the first edition, but now using the Computer Modern fonts, which I feel give better readability than the font used previously.
, like the first edition, but now using the Computer Modern fonts, which I feel give better readability than the font used previously.
A huge amount of thought has gone into the book. It has a 9 page initial section called Preliminaries that lists key definitions, a 51 page glossary, a 12 page notation index, and a 54 page main index.
For quite a while I was puzzled by index entries such as “50-12–17”. I eventually noticed that the second dash is an en-dash and realized that the notation means “pages 12 to 17 of article 50”. This should have been noted at the start of the index.
In fact my only serious criticism of the book is the index. It is simply too hard to find what you are looking for. For example, there is no entry for Gerhsgorin’s theorem, which appears on page 16-6. Nor is there one for Courant-Fischer, whose variational eigenvalue characterization theorem is on page 16-4. There is no index entry under “exponential”, but the matrix exponential appears under two other entries and they point to only one of the various pages where the exponential appears. The index entry for Loewner partial ordering points to Chapter 22, but the topic also has a substantial appearance in Section 9.5. Surprisingly, most of these problems were not present in the index to the first edition, which is also two pages longer!
Fortunately the glossary is effectively a high-level index with definitions of terms (and an interesting read in itself). So to get the best from the book use the glossary and index together!
An alternative book for reference is Bernstein’s Matrix Mathematics (second edition, 2009), which has an excellent 100+ page index, but no glossary. I am glad to have both books on my shelves (the first edition at home and the second edition at work, or vice versa—these books are too heavy to carry around!).
Overall, Leslie Hogben has done an outstanding job to produce a book of this size in a uniform style with such a high standard of editing and typesetting. Ideally one would have both the hard copy and the ebook version, so that one can search the latter. Unfortunately, the ebook appears to have the same relatively high list price as the hard copy (“unlimited access for $169.95”) and I could not see a special deal for buying both. Nevertheless, this is certainly a book to ask your library to order and maybe even to purchase yourself.


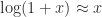
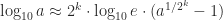
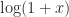
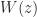
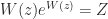
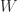
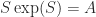
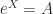
 be an
be an  real or complex matrix. Consider the principal logarithm—the one for which
real or complex matrix. Consider the principal logarithm—the one for which 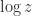 has imaginary part in
has imaginary part in ![(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002) —and define
—and define 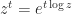 for
for  (an important special case being
(an important special case being  for an integer
for an integer  ) .
) . for all
for all  for all
for all  whenever
whenever  commute.
commute.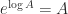 is always true.
is always true.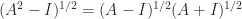 is false.
is false. and a power
and a power  in the above expressions stands for the families of all possible logarithms and powers then the identities are all true. But from a computational viewpoint we are usually concerned with a particular branch of each function, the principal branch, so equality cannot be taken for granted.
in the above expressions stands for the families of all possible logarithms and powers then the identities are all true. But from a computational viewpoint we are usually concerned with a particular branch of each function, the principal branch, so equality cannot be taken for granted.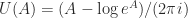 , and it arises from the scalar unwinding number introduced by Corless, Hare and Jeffrey in 1996
, and it arises from the scalar unwinding number introduced by Corless, Hare and Jeffrey in 1996 
 , so the relation in the first quiz question is clearly valid when
, so the relation in the first quiz question is clearly valid when 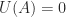 , which is the case when the eigenvalues of
, which is the case when the eigenvalues of 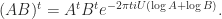
 and the matrix
and the matrix  has eigenvalues with imaginary parts in
has eigenvalues with imaginary parts in 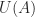 ? The following incomplete MATLAB code implements the Schur algorithm developed in the paper. The
? The following incomplete MATLAB code implements the Schur algorithm developed in the paper. The 


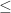 . Ground level dots are produced by
. Ground level dots are produced by  entry
entry  cannot be stored exactly in floating point arithmetic.
cannot be stored exactly in floating point arithmetic. 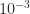 ).
). 


