These four economists got together to write their paper about surname-sharing economist co-authors with the ulterior motive of beating the previous record of three.
A weaker requirement is surnames beginning with the same letter, for which we offer
Here is a run of four surnames beginning with consecutive letters:
D. Bremner, T. M. Chan, E. D. Demaine, J. Erickson, F. Hurtado, J. Iacono, S. Langerman, and P. Taslakian. Necklaces, convolutions, and . In Y. Azar and T. Erlebach, editors, Algorithms–ESA 2006, volume 4168 of Lecture Notes in Computer Science, pages 160–171. Springer-Verlag, Berlin, 2006.
The next paper goes even better by starting at “A”:
According to Freeman Dyson, “Bethe had nothing to do with the writing of the paper but allowed his name to be put on it to fill the gap between Alpher and Gamow.”
Names Far Apart
In contrast to the previous section, here we are looking for names that are spaced as far apart in the alphabet as possible. For two authors this is the most extreme case:
H. Ashley and G. Zartarian, Piston Theory—A New Aerodynamic Tool for the Aeroelastician, Journal of the Aeronautical Sciences 23, 1109-1118, 1956.
Cyclic Repetition
Can we find an author list in which the surnames repeat cyclically? I offer
However, it would be hard to beat the next paper, whose author (Walter Russell Brain) not only got his name into the title, but also published the paper in a journal of the same name: a triple whammy!
Image courtesy of Stuart Miles at FreeDigitalPhotos.net.
Lists are common in all forms of writing. The list items can be included within the text or put on separate lines. Separate lines are used in order to draw attention to the items, to ease reading when the items are long or numerous, or to facilitate cross-reference to specific items.
The two main types of lists are enumerated lists, in which the items are numbered or labelled alphabetically, and itemized lists, in which each entry is preceded by a marker such as a bullet symbol. In these are produced by the enumerate and itemize environments, respectively. (The basic enumerate environment allows only numbers as labels, but the enumerate package extends the environment to allow letters, too.)
I have long felt unsure about how to punctuate lists, and especially the sentence that introduces the list. Advice is hard to find in books on English usage and there seems to be no agreed way to do it. Some recent reading, namely of the TUGboat article Makings Lists: A Journey Into Unknown Grammar by James. R. Hunt and the book Making a Point: The Pernickity Story of English Punctuation by David Crystal, has clarified my thinking. I will now explain how I intend to format lists in future.
My approach is based on a key principle, which stems from the fact that in English all sentences must be complete, and not mere fragments. (There is no universally agreed definition of what distinguishes a sentence from a fragment, but a sentence is usually required to contain a verb.) The principle is that
if the labels in a list are removed then what remains should make one or more complete and correctly punctuated sentences.
Here are three examples that are correctly formatted according to this principle.
Example 1. Programming languages from three decades will be compared:
C++ (1985),
Python (1991), and
Julia (2012).
This type of list could readily be collapsed inline into a regular sentence: “Programming languages from three decades will be compared: C++ (1985), Python (1991), and Julia (2012).” The author must judge whether the list form, with its clearer separation of the items, is preferable. Note the “and” after the second item. This is needed, though I think many people would find the example acceptable without it.
Example 2. We used three different algorithms in the experiments. The table reports the performance of
Algorithm 3.1 (based on a Taylor series),
Algorithm 3.2 (with parameter ), and
Algorithm 3.3 (with tolerance ).
The sentence that precedes the list does not end with a colon. If it did, then the principle would be violated.
Example 3. Before printing the paper carry out the following steps.
Run the paper through .
Run the paper through BibTeX.
Repeat steps 1 and 2 until no warnings occur about unresolved references.
In this example each list element is a complete sentence. The numbering of the elements is appropriate because they have a definite order. In some other list in which the ordering is arbitrary one might nevertheless decide to number the elements in order to be able to refer to the elements later on.
The next example does not conform to the principle.
Example 4. We will use three test matrices.
rosser: a classic symmetric matrix with close and repeated eigenvalues,
hilb: the Hilbert matrix, and
pascal: a matrix with elements taken from Pascal’s triangle.
If we remove the list markers then the list items turn into a sentence fragment containing no verb. I suspect few people would object to the formatting of this example. But we can easily modify it to conform.
Example 4 (modified). We will use three test matrices:
rosser, a classic symmetric matrix with close and repeated eigenvalues;
hilb, the Hilbert matrix; and
pascal, a matrix with elements taken from Pascal’s triangle.
Note the use of the semicolons to separate the items, which now contain commas. I much prefer the modified example, although in the past I might have been happy with the original.
Of course, style guidelines for individual publications may override what I have said above. However, my experience is that academic publishers tend not to change authors’ lists unless they are clearly grammatically incorrect. For example the SIAM Style Manual advises copy editors “Retain the author’s list style as long as it’s consistent”.
Finally, I note that the The Princeton Companion to Applied Mathematics follows the principle recommended here, though that is purely a coincidence. I did not think about list punctuation at all while working on the book, leaving it in the hands of copy editor Sam Clark (T&T Productions, London).
BibTeX is an important part of my workflow in writing papers and books. Here are three tips for getting the most out of it.
1. DOI and URL Links from Bibliography Entries
A digital object identifier (DOI) provides a persistent link to an object on the web, via the server at http://dx.doi.org. Most scholarly journals now assign DOIs to papers, and many papers from the past have been retrofitted with them. Books can also have DOIs, as in SpringerLink or the SIAM ebook program.
It is very convenient for a reader of a PDF document to be able to access items from the bibliography by clicking on part of the item. The links can be constructed from a DOI, and if one does not exist a URL can be used instead. How can we produce such links automatically with BibTeX? Simply add fields doi or url and use an appropriate BibTeX style (BST) file. I’m not aware of any standard BST file that handles these fields, so I modified my own BST file using these tips. The result, myplain2-doi.bst, is available in this GitHub repository. Example bib entries that work with it are as follows.
@article{ahr13,
author = "Awad H. Al-Mohy and Nicholas J. Higham and Samuel D. Relton",
title = "Computing the {Fr{\'e}chet} Derivative of the Matrix Logarithm
and Estimating the Condition Number",
journal = "SIAM J. Sci. Comput.",
volume = 35,
number = 4,
pages = "C394-C410",
year = 2013,
doi = "10.1137/120885991",
created = "2012.07.05",
updated = "2013.08.06"
}
@article{hpp09,
author = "Horn, Roger A. and Piazza, Giuseppe and Politi, Tiziano",
title = "Explicit Polar Decompositions of Complex Matrices",
journal = "Electron. J. Linear Algebra",
volume = "18",
pages = "693-699",
year = "2009",
url = "https://eudml.org/doc/233457",
created = "2013.01.02",
updated = "2015.07.15"
}
The journal in which the second example appears is one that does not itself provide DOIs or URLs for papers. However, the European Digital Mathematics Library provides URLs for this journal, so I have used the appropriate one from there.
My BST file hyperlinks the title of each item to the corresponding DOI or URL. For an example of the style in use, see the typeset version of njhigham.bib, for which here is a direct link. An alternative style is simply to print the DOI or URL with a hyperlink.
2. Web page from Bib File via BibBase
Once you have made a bib file of a group of publications a natural question is how you can automatically generate a web page that displays the publications in an easily browsable format. A great way to do this is with BibBase. You simply point BibBase at your online bib file and it generates some JavaScript, PHP, or iFrame code. When you include that code in your a web page it displays the Bib entries sorted by year, with each DOI or URL field made clickable and each BibTeX entry revealable. A menu allows sorting by author, type, or year and the list can be folded. My bib file njhigham.bib formatted by BibBase is available here.
BibBase is free to use. It was first released a few years ago and is still being developed, with improved support for LaTeX and for special characters added recently. Keep up to date with developments by following the BibBase Twitter feed.
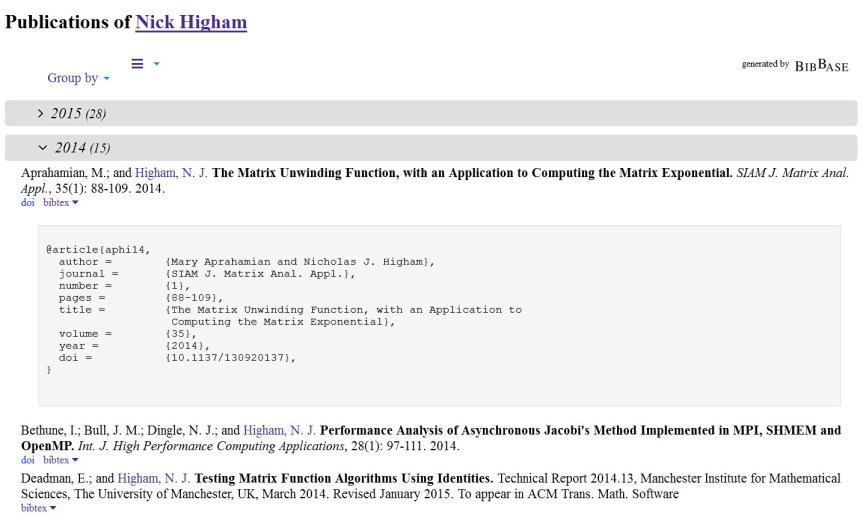
Here are two screenshots. The first shows part of the default layout, with outputs from 2015 folded and one bib entry revealed.
The second screenshot shows part of the list ordered by author.
3. Bib Entry from DOI
If you happen to know the DOI of a paper and want to obtain a bib entry, go to the doi2bib service and type in your DOI. For further information see this blog post and follow the doi2bib Twitter feed.
The Victoria University of Manchester (VUM) merged with the University of Manchester Institute of Science and Technology (UMIST) in 2004 to form The University of Manchester. The two former Departments of Mathematics joined together to form the School of Mathematics. In 2007 the School moved into a new building at the heart of the campus: the Alan Turing Building. The School is one of the largest integrated schools of mathematics in the UK, with around 75 permanent lecturing staff and over 1000 undergraduates.
As the School moves ahead it is important to keep an eye on the past, and to maintain valuable historical information about the predecessor departments. I know from emails I receive and contact with alumni (most recently at a reception in London last summer) that former students and staff like to look at photos and documents relating to their time here.
I have previously made available various documents and photos concerning the VUM Mathematics Tower on Oxford Road.
Now I have scanned five documents that provided information for prospective and current VUM mathematics undergraduates.
Image courtesy of Stuart Miles at FreeDigitalPhotos.net.
This blog, which is almost three years old, is titled “Applied mathematics, software and workflow”. Workflow refers to everything involved in a research activity except the actual research. It’s about how to do many different things: edit and typeset a document, store and access your bibliographic references, carry out reproducible numerical experiments, produce figures, back up your files, collaborate with others, and so on. These tasks all need to be done multiple times, so small gains in efficiency can have a big payoff in the long run.
Workflow is not just about efficiency, though, or about producing the best possible end result. It’s also about enjoying carrying out the various tasks. Don Knuth put it perfectly when he said, in The Art of Computer Programming (Volume 2, Seminumerical Algorithms),
The enjoyment of one’s tools is an essential ingredient of successful work.
A search of this blog shows that I have barely used the term “workflow” so far. But a number of posts relate to this topic, namely
those on Emacs: my favourite editor and a key component of my own workflow,
It is always interesting to look at the acknowledgements section of a paper, if one is present, in the hope of finding something (often unintentionally) humorous or unexpected. Here are some that I’ve collected, all from published mathematics papers.
Faulty English
The first group comprises examples where the acknowledgement doesn’t say what it was meant to say. The explanatory comments are aimed at those whose first language is not English or who are new to the publishing game.
“I would like to thank the unknown referees for their valuable comments.”
This is quite a common usage. Unknown should be replaced by anonymous in order to avoid the interpretation that the referee is someone who is not known in the community.
“I thank the anonymous referees, particularly Dr. J. R. Ockendon, for numerous suggestions and for the source of references.”
A referee is not anonymous if his name is known.
“I am grateful to the referee whose suggestions greatly improved this paper.”
Ambiguous. Were there other referees whose suggestions did not improve the paper? A comma after “referee” would avoid the ambiguity.
“I am also glad about some suggestions of the referee.”
Non-idiomatic and implies that the author did not like some other suggestions of the referee.
“The authors wish to thank the valuable suggestions of the referee.”
It’s the referee who should be thanked, not the referee’s suggestions.
Unexpected Thanks
Here are some more unusual acknowledgements. The first, from
“We thank Dr. A. Bunse-Gerstner for many helpful discussions (and the German police for a speeding ticket during one discussion). We also thank the referee for several insightful comments.”
What a shame that the discussion did not take place on an unrestricted autobahn.
Sometimes an acknowledgement is about help that has “oiled the wheels”. The authors of
The authors wish to thank Mr. and Mrs. Peter Taplin of the Stone House Hotel, near Hawes, North Yorkshire whose helpful service and friendly hospitality eased the preparation of this paper considerably.
It seems that, thirty years later, the Stone House Hotel is still up and running with the same hosts. Let this serve as an unsponsored recommendation.
Jack Williams passed away on November 13th, 2015, at the age of 72.
Jack obtained his PhD from the University of Oxford Computing Laboratory in 1968 and spent two years as a Lecturer in Mathematics at the University of Western Australia in Perth. He was appointed Lecturer in Numerical Analysis at the University of Manchester in 1971.
He was a member of the Numerical Analysis Group (along with Christopher Baker, Ian Gladwell, Len Freeman, George Hall, Will McLewin, and Joan Walsh) that, together with numerical analysis colleagues at UMIST, took the subject forward at Manchester from the 1970s onwards.
Jack’s main research area was approximation theory, focusing particularly on Chebyshev approximation of real and complex functions. He also worked on stiff ordinary differential equations (ODEs). His early work on Chebyshev approximation in the complex plane by polynomials and rationals was particularly influential and is among his most-cited. Example contributions are
His later work on discrete Chebyshev approximation was of particular interest to me as it involved linear systems with Chebyshev-Vandermonde coefficient matrices, which I, and a number of other people, worked on a few years later:
On the differential equations side, Jack wrote the opening chapter “Introduction to discrete variable methods” of the proceedings of a summer school organized jointly by the University of Liverpool and the University of Manchester in 1975 and published in G. Hall and J. M. Watt, eds, Modern Numerical Methods for Ordinary Differential Equations, Oxford University Press, 1976. This book’s timely account of the state of the art, covering stiff and nonstiff problems, boundary value problems, delay-differential equations, and integral equations, was very influential, as indicted by its 549 citations on Google Scholar. Jack contributed articles on ODEs and PDEs to three later Liverpool–Manchester volumes (1979, 1981, 1986).
Jack’s interests in approximation theory and differential equations were combined in his later work on parameter estimation in ODEs, where a theory of Chebyshev approximation applied to solutions of parameter-dependent ODEs was established, as exemplified by
Jack spent a sabbatical year in the Department of Computer Science at the University of Toronto, 1976–1977, at the invitation of Professor Tom Hull. Over a number of years several visits between Manchester and Toronto were made in both directions by numerical analysts in the two departments.
It’s a fact of academic life that seminars can be boring and even impenetrable. Jack could always be relied on to ask insightful questions, whatever the topic, thereby improving the experience of everyone in the room.
Jack was an excellent lecturer, who taught at all levels from first year undergraduate through to Masters courses. He was confident, polished, and entertaining, and always took care to emphasize practicalities along with the theory. He had the charisma—and the loud voice!—to keep the attention of any audience, no matter how large it might be.
He studied Spanish at the Instituto Cervantes in Manchester, gaining an A-level in 1989 and a Diploma Basico de Espanol Como Lengua Extranjera from the Spanish Ministerio de Educación y Ciencia in 1992. He subsequently set up a four-year degree in Mathematics with Spanish, linking Manchester with Universidad Complutense de Madrid.
Jack was promoted to Senior Lecturer in 1996 and took early retirement in 2000. He continued teaching in the department right up until the end of the 2014/2015 academic year.
I benefited greatly from Jack’s advice and support both as a postgraduate student and when I began as a lecturer. My office was next to his, and from time to time I would hear strains of classical guitar, which he studied seriously and sometimes practiced during the day. For many years I shared pots of tea with him in the Senior Common Room at the refectory, where a group of mathematics colleagues met for lunchtime discussions.
Jack was gregarious, ever cheerful, and a good friend to many of his colleagues. He will be sadly missed.
George Hall, Jack WIlliams and Des Higham at the Conference on Computational Ordinary Differential Equations, London, England, 1989.
The singular value decomposition (SVD) is one of the most important tools in matrix theory and matrix computations. It is described in many textbooks and is provided in all the standard numerical computing packages. I wrote a two-page article about the SVD for The Princeton Companion to Applied Mathematics, which can be downloaded in pre-publication form as an EPrint.
The polar decomposition is a close cousin of the SVD. While it is probably less well known it also deserves recognition as a fundamental theoretical and computational tool. The polar decomposition is the natural generalization to matrices of the polar form for complex numbers, where , is the imaginary unit, and . The generalization to an matrix is , where is with orthonormal columns and is and Hermitian positive semidefinite. Here, plays the role of in the scalar case and the role of .
It is easy to prove existence and uniqueness of the polar decomposition when has full rank. Since implies , we see that must be the Hermitian positive definite square root of the Hermitian positive definite matrix . Therefore we set , after which is forced. It just remains to check that this has orthonormal columns: .
Many applications of the polar decomposition stem from a best approximation property: for any matrix the nearest matrix with orthonormal columns is the polar factor , for distance measured in the 2-norm, the Frobenius norm, or indeed any unitarily invariant norm. This result is useful in applications where a matrix that should be unitary turns out not to be so because of errors of various kinds: one simply replaces the matrix by its unitary polar factor.
However, a more trivial property of the polar decomposition is also proving to be important. Suppose we are given and we compute the eigenvalue decomposition , where is diagonal with the eigenvalues of on its diagonal and is a unitary matrix of eigenvectors. Then is an SVD! My PhD student Pythagoras Papadimitriou and I proposed using this relation to compute the SVD in 1994, and obtained speedups by a factor six over the LAPACK SVD code on the Kendall Square KSR1, a shared memory parallel machine of the time.
Yuji Nakatsukasa and I recently revisited this idea. In a 2013 paper in the SIAM Journal of Scientific Computing we showed that on modern architectures it is possible to compute the SVD via the polar decomposition in a way that is both numerically stable and potentially much faster than the standard Golub–Reinsch SVD algorithm. Our algorithm has two main steps.
Compute the polar decomposition by an accelerated Halley algorithm called QDWH devised by Nakatsukasa, Bai, and Gygi (2010), for which the main computational kernel is QR factorization.
Compute the eigendecomposition of the Hermitian polar factor by a spectral divide and conquer algorithm. This algorithm repeatedly applies QDWH to the current block to compute an invariant subspace corresponding to the positive or negative eigenvalues and thereby divides the problem into two smaller pieces.
The polar decomposition is fundamental to both steps of the algorithm. While the total number of flops required is greater than for the standard SVD algorithm, the new algorithm has lower communication costs and so should be faster on parallel computing architectures once communication costs are sufficiently greater than the costs of floating point arithmetic. Sukkari, Ltaief, and Keyes have recently shown that on a multicore architecture enhanced with multiple GPUs the new QDWH-based algorithm is indeed faster than the standard approach. Another interesting feature of the new algorithm is that it has been found experimentally to have better accuracy.
The Halley iteration that underlies the QDWH algorithm for the polar decomposition has cubic convergence. A version of QDWH with order of convergence seventeen, which requires just two iterations to converge to double-precision accuracy, has been developed by Nakatsukasa and Freund (2015), and is aimed particularly at parallel architectures. This is a rare example of an iteration with a very high order of convergence actually being of practical use.
Matrix analysis and numerical linear algebra are two very active, and closely related, areas of research. Matrix analysis can be defined as the theory of matrices with a focus on aspects relevant to other areas of mathematics, while numerical linear algebra (also called matrix computations) is concerned with the construction and analysis of algorithms for solving matrix problems, as well as related topics such as problem sensitivity and rounding error analysis.
My article Numerical Linear Algebra and Matrix Analysis for The Princeton Companion to Applied Mathematics gives a selective overview of these two topics. The table of contents is as follows.
1 Nonsingularity and Conditioning
2 Matrix Factorizations
3 Distance to Singularity and Low-Rank Perturbations
4 Computational Cost
5 Eigenvalue Problems
5.1 Bounds and Localization
5.2 Eigenvalue Sensitivity
5.3 Companion Matrices and the Characteristic Polynomial
5.4 Eigenvalue Inequalities for Hermitian Matrices
5.5 Solving the Non-Hermitian Eigenproblem
5.6 Solving the Hermitian Eigenproblem
5.7 Computing the SVD
5.8 Generalized Eigenproblems
6 Sparse Linear Systems
7 Overdetermined and Underdetermined Systems
7.1 The Linear Least Squares Problem
7.2 Underdetermined Systems
7.3 Pseudoinverse
8 Numerical Considerations
9 Iterative Methods
10 Nonnormality and Pseudospectra
11 Structured Matrices
11.1 Nonnegative Matrices
11.2 M-Matrices
12 Matrix Inequalities
13 Library Software
14 Outlook
 ,
,  , and Related Matrix Functions by Contour Integrals
, and Related Matrix Functions by Contour Integrals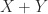

 these are produced by the
these are produced by the  ), and
), and
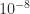 ).
).







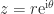 for complex numbers, where
for complex numbers, where  ,
, 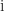 is the imaginary unit, and
is the imaginary unit, and ![\theta\in(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002) . The generalization to an
. The generalization to an 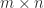 matrix is
matrix is 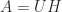 , where
, where  is
is  is
is  and Hermitian positive semidefinite. Here,
and Hermitian positive semidefinite. Here, 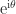 in the scalar case and
in the scalar case and  .
. has full rank. Since
has full rank. Since 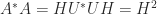 , we see that
, we see that 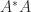 . Therefore we set
. Therefore we set  , after which
, after which 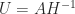 is forced. It just remains to check that this
is forced. It just remains to check that this 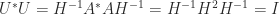 .
. , where
, where  is diagonal with the eigenvalues of
is diagonal with the eigenvalues of  is a unitary matrix of eigenvectors. Then
is a unitary matrix of eigenvectors. Then  is an SVD! My PhD student Pythagoras Papadimitriou and I
is an SVD! My PhD student Pythagoras Papadimitriou and I 